 Los Enterprise Java Beans (EJB) son componentes del lado del servidor para la plataforma Java Enterprise Edition (Java EE), que apuntan a crear un desarrollo rápido y simple para aplicaciones distribuidas, transaccionales, seguras y portables.
Los Enterprise Java Beans (EJB) son componentes del lado del servidor para la plataforma Java Enterprise Edition (Java EE), que apuntan a crear un desarrollo rápido y simple para aplicaciones distribuidas, transaccionales, seguras y portables.
EJB 3.1 trae un nuevo conjunto de características que mejoran el potencial de esta tecnología. Es una versión muy importante que traerá nuevas capacidades faltantes a estos componentes. En este artículo vamos a repasar los elementos más importantes de EJB 3.1.
Vista sin interfaz
EJB 3.1 introduce el concepto de vista sin interfaz, que consiste en una variación de la vista Local, la cual expone todos los métodos públicos de un bean. Los Session Beans no están obligados a implementar una interfaz. El contenedor de EJB provee una implementación a la referencia a una vista sin interfaz, lo que le permite al cliente invocar cualquier método público de un bean, y por supuesto contar con transacciones, seguridad y comportamiento con interceptores.
Todos los métodos públicos del bean (incluyendo aquellos definidos en superclases) están disponibles en la vista sin interfaz. Un cliente puede obtener una referencia a esta vista haciendo un lookup JNDI o inyectando la dependencia, tal cual se hace con las vistas locales o remotas.
A diferencia de las vistas locales o remotas, en donde la referencia consiste de la interfaz local/remota respectivamente, la referencia a una vista sin interfaz se declara como la clase del bean.
El siguiente ejemplo de código muestra cómo un servlet puede acceder a una vista sin interfaz. La referencia en el cliente es la vista sin interfaz ByeEJB, es decir, la clase del bean. El EJB no implementa ninguna interfaz. La referencia al EJB se obtiene por inyección de dependencia.
ByeServlet
(...) @EJB private ByeEJB byeEJB; public String sayBye() { StringBuilder sb = new StringBuilder(); sb.append("<html><head>"); sb.append("<title>ByeBye</title>"); sb.append("</head><body>"); sb.append("<h1>" + byeEJB.sayBye() + "</h1>"); sb.append("</body></html>"); return sb.toString(); } (...)
ByeEJB
@Stateless public class ByeEJB { public String sayBye() { return "Bye!"; } }
Como el tipo de la referencia al EJB es la clase del bean existen ciertas limitaciones:
- El cliente nunca puede usar al operador new para adquierir la referencia.
- Si se intenta invocar un método que no es público se lanza una EJBException.
- No se puede hacer ninguna presunción sobre la implementación interna de la vista sin interfaz. Aunque la referencia corresponda con el tipo de la clase del bean, no hay correspondencia entre la implementación referenciada y la implementación del bean.
Si el bean no expone ninguna interfaz remota o local, entonces el contenedor tiene que dejar disponible una vista sin interfaz. En cambio, si el bean expone al menos una interfaz remota o una local, entonces el contenedor no provee una vista sin interfaz (a menos que se pida explícitamente usando la anotación LocalBean).
Esta característica permite crear EJB sin interfaces, lo que simplifica el desarrollo. Quizás en el futuro tengamos también vistas remotas sin interfaz.
Singleton
La mayoría de las aplicaciones tuvieron alguna vez un bean singleton, es decir, un bean que se instancia una única vez por aplicación. Varios proveedores brindan soporte para esto, permitiendo especificar la cantidad máxima de instancias en un descriptor propietario. Estos "arreglos" rompen el principio de "escribir una vez, desplegar en cualquier lado", y por lo tanto era responsabilidad de la especificación estandarizar este aspecto. EJB 3.1 finalmente introduce los Singleton Session Beans.
Ahora hay tres tipos de Session Beans: stateless, stateful y singleton. Los Singleton Session Beans se identifican por la anotación Singleton y se instancian una única vez por aplicación. La instancia existente se comparte entre todos los clientes, y permite accesos concurrentes.
La vida de un Singleton Bean comienza cuando el contenedor realiza la instanciación (por instanciación nos refererimos a la instanciación, inyección de dependencias y ejecución de los callback PostConstruct). El contenedor es responsable de decidir cuándo se construye el bean, aunque el desarrollador puede decirle al contenedor que inicialice el bean durante el inicio de la aplicación, usando la anotación Startup. Más aún, la anotación Startup permite definir dependencias hacia otros Singleton Beans. El contenedor debe inicializar todos los beans marcados con Startup antes de comenzar a responder peticiones de los clientes.
El siguiente ejemplo muestra cómo funcionan las dependencias. La instanciación del Singleton A la decide el contenedor ya que no contiene una anotación Startup y no hay ningún otro bean en el que dependa. El Singleton B se instancia durante el inicio de la aplicación y antes del Singleton D y del Singleton E (E depende de D, que depende de B). Aunque el Singleton B no tenga la anotación Startup, hay otros singletons que lo tienen como dependencia. El Singleton C se inicia durante el inicio de la aplicación, antes del Singleton E, igual que le Singleton D. Por último, el Singleton E será el último en instanciarse durante el inicio de la aplicación.
@Singleton public class A { (...) } @Singleton public class B { (...) } @Startup public class C { (...) } @Startup(DependsOn="B") @Singleton public class D { (...) } @Startup(DependsOn=({"C", "D"}) @Singleton public class E { (...) }
Nótese que el orden definido en múltiples dependencias no se considera en tiempo de ejecución. Por ejemplo, el hecho de que E dependa de C y D no significa que C se va a instanciar antes que D. Si se necesita esto hay que hacer una dependencia entre D y C.
Un singleton puede definir una dependencia de inicio contra un singleton que existe en otro módulo.
El contenedor es responsable de destruir todos los singleton durante el apagado de la aplicación, ejecutando los callback PreDestroy. Las dependencias de inicio se consideran durante este proceso, es decir, si A depende de B, entonces B va a estar disponible cuando se destruya A.
Un Singleton Bean mantiene estado entre invocaciones de clientes, pero este estado no sobrevive al apagado de la aplicación o a una caida del contenedor. Para manipular las invocaciones concurrentes de clientes el desarrollador tiene que definir la estrategia de concurrencia. La especificación define dos alternativas:
- Container-Managed Concurrency (CMC), o concurrencia gestionada por el contenedor, en donde el contenedor gestiona el acceso a la instancia del bean. Esta es la estrategia predeterminada.
- Bean-Managed Concurrency (BMC), o concurrencia gestionada por el bean, en donde el contenedor no realiza ninguna intervención para gestionar la concurrencia, permitiendo así accesos concurrentes, y delegando la responsabilidad de sincronización al desarrollador. Con BMC se pueden usar primitivas de sincronización como sinchronized y volatile para coordinar a múltiples hilos de diferentes clientes.
CMC será la elección preferida la mayoría de las veces. El contenedor gestiona la concurrencia usando metadata de bloqueos. A cada método se le asocia un bloqueo de lectura o escritura. Un bloqueo de lectura indica que el método puede ser accedido por múltiples invocaciones concurrentes. Un bloqueo de escritura indica que el método sólo puede accederse por un cliente a la vez.
El bloqueo predeterminado es de escritura. Esto se puede cambiar usando la anotación Lock, que se puede aplicar a la clase, a la interfaz de negocio, o a un método.
Cuando un método tiene bloqueo por escritura, el contenedor sólo permite que un cliente por vez lo ejecute y mantiene en espera al resto hasta que el método esté disponible. El cliente espera indefinidamente, a menos que se use la anotación AccessTimeout, que determina un tiempo máximo (en milisegundos) de espera para el cliente, luego del cual se lanza una ConcurrentAccessTimeoutException.
A continuación vemos varios ejemplos que ilustran el uso de Singleton Beans CMC. El Singleton A define explícitamente el uso de CMS, aunque no es necesario porque es el modo predeterminado. El Singleton B no define la estrategia de concurrencia (por lo que será CMC) y define que los métodos expuestos usan bloqueos de escritura (aunque no sea necesario, porque es el predeterminado). El Singleton C utiliza bloqueos de lectura para todos los métodos. Lo mismo ocurre en el Singleton D, con la diferencia que el método sayBye tiene un bloqueo de escritura. Por último, el Singleton E utiliza bloqueos de escritura, y cualquier cliente va a obtener una ConcurrentAccessTimeoutException si se mantiene en espera por 10 segundos.
@Singleton @ConcurrencyManagement(CONTAINER) public class A { (...) } @Singleton @Lock(WRITE) public class B { (...) } @Singleton @Lock(READ) public class C { (...) } @Singleton @Lock(READ) public class D { (...) @Lock(WRITE) public String sayBye() { (...) } (...) } @Singleton @AccessTimeout(10000) public class E { (...) }
En el caso de los clusters, existirá una instancia de cada Singleton por cada JVM en donde esté desplegada la aplicación.
Hasta EJB 3, cualquier excepción de sistema ocasionaba que el EJB fuera descartado. Esto no aplica para los Singleton Bean, porque deben permanecer activos hasta que se apague la aplicación.
Igual que con los Stateless Beans, los Singleton pueden ser expuestos como servicios web.
Invocaciones asincrónicas
Las invocaciones asincrónicas de métodos de un Session Bean es una de las características más interesantes de esta nueva versión. Puede utilizarse en todos los tipos de beans, en todas las vistas. Las especificación define que una invacación asincrónica tiene que retornar al cliente antes de que el contenedor entregue la invocación a la instancia del bean. Esto eleva la utilización de los Session Bean a un nuevo nivel, permitiendo que los desarrolladores se beneficien de invocaciones asincrónicas a los beans, lanzando así flujos de procesos en paralelo.
Un método se marca como asincrónico usando la anotación Asynchronous, la cual puede aplicarse a un método o a una clase. Los siguientes ejemplos ilustran distintos casos de uso de esta anotación. El Bean A hace que todos sus métodos de negocio sean asincrónicos. El Singleton B define al método flushBy como asincrónico. Para el bean stateless C todos los métodos invocados desde su interfaz local Clocal son asincrónicos, pero si se invocan desde su interfaz remota son sincrónicos. Por lo tanto la invocación del mismo método puede comportarse diferente dependiendo de la interfaz que se utilice. Por último, el método flushBy del bean D se invoca de manera asincrónica cuando se lo accede a través de la interfaz local.
@Stateless @Asynchronous public class A { (...) } @Singleton public class B { (...) @Asynchronous public void flushBye() { (...) } (...) } @Stateless public class C implements CLocal, CRemote { public void flushBye() { (...) } } @Local @Asynchronous public interface CLocal { public void flushBye(); } @Remote public interface CRemote { public void flushBye(); } @Stateless public class D implements DLocal { (...) } @Local public interface DLocal { (...) @Asynchronous public void flushBye(); (...) }
El tipo de retorno de un método asincrónico debe ser void o Future
La interfaz Future se agregó a Java 5 y brinda cuatro métodos:
- cancel(boolean mayInterruptIfRunning) - intenta cancelar la ejecución del método asincrónico. El contenedor intentará cancelar la invocación si todavía no fue iniciada. Si la cancelación resulta exitosa el método devuelve true, sino false. El parámetro mayInterruptIfRunning controla, en caso de que no pueda detenerse la invocación, si el bean destino tiene visibilidad del pedido de cancelación del cliente.
- get - retorna el resultado del método cuando termina. Este método tiene dos versiones sobrecargadas, una que se bloquea hasta que termine la ejecución, y la otra que recibe un timeout como parámetro.
- isCancelled - indica si el método fue cancelado.
- isDone - indica si el método terminó exitosamente.
La especificación indica que el contenedor debe proveer la clase AsyncResult
@Asynchronous public Future<String> sayBye() { String bye = executeLongQuery(); return new AsyncResult<String>(bye); }
El uso del tipo de retorno Future
@Stateless public class ByeEJB implements ByeLocal, ByeRemote { public String sayBye() { (...) } } @Local @Asynchronous public interface sayBye { public Future<String> flushBye(); } @Remote public interface ByeRemote { public String sayBye(); }
La interfaz SessionContext está mejorada para incluir al método wasCancelCalled, el cual retorna true si el cliente invoca al método Future.cancel con el parámetro mayInterruptIfRunning en true.
@Resource SessionContext ctx; @Asynchronous public Future<String> sayBye() { String bye = executeFirstLongQuery(); if (!ctx.wasCancelCalled()){ bye += executeSecondLongQuery(); } return new AsyncResult<String>(bye); }
Nótese que el método get de la interfaz Future declara una ExceutionException. Si el método asincrónico lanza una excepción de aplicación, entonces esta excepción se propagará al cliente a través de una ExecutionException. La excepción original estará disponible usando el método getCause.
@Stateless public class ByeEJB implements ByeLocal { public String sayBye() throws MyException { throw new MyException(); } } @Local @Asynchronous public interface ByeLocal { public Future<String> sayBye(); } //Client @Stateless public class ClientEJB { @EJB ByeLocal byeEjb; public void invokeSayBye() { try { Future<String> futStr = byeEjb.sayBye(); } catch(ExecutionException ee) { String originalMsg = ee.getCause().getMessage(); System.out.println("Mensaje original del error:" + originalMsg); } } }
El contexto de la transacción del cliente no se propaga a la ejecución del método asincrónico. Por lo tanto podemos concluir que:
- Si el método m se define con transacción REQUIRED, entonces va a funcionar como REQUIRES_NEW.
- Si el método m se define con transacción MANDATORY, entonces siempre se lanzará una TransactionRequiredException.
- Si el método m se define con transacción SUPPORTS, entonces nunca va a ejecutarse en un contexto transaccional.
En cuanto a la propagación de seguridad, la misma funciona igual que con métodos sincrónicos.
Nombres JNDI globales
Esta es una característica que se venía esperando hace mucho. La asignación de nombres JNDI globales a los EJB siempre se implementó de manera propietaria para cada proveedor, lo que ocasionaba varios problemas. La misma aplicación que se desplegaba en contenedores de distintos proveedores podían quedar con los EJB con nombres JNDI distintos, provocando problemas en los clientes. Además, algunos proveedores hacían que las interfaces locales se pudieron obtener via JNDI, mientras que otros no.
La especificación ahora define nombres JNDI globales para registrar a los EJB. Dicho de otra forma, ahora tenemos nombres JNDI portables.
Cada nombre JNDI portable tiene la siguiente sintaxis:
java:global[/
La tabla siguiente describe los distintos componentes:
|
Componente |
Descripción |
Obligatorio |
|
app-name |
El nombre de la aplicación en donde está empaquetado el bean. El valor predeterminado es el nombre del ear (sin la extensión) a menos que se especifique en el archivo application.xml |
No |
|
module-name |
El nombre del módulo en donde está empaquetado el bean. El valor predeterminado es el nombre del módulo (sin la extensión) a menos que se especifique en el archivo ejb-jar.xml |
Si |
|
bean-name |
El nombre del bean. El valor predeterminado es el nombre no calificado de la clase del Session bean, a menos que se especifique en el atributo name de la anotación Stateless / Stateful / Singleton o en el descriptor de despliegue. |
Si |
|
Fully-qualified-interface-name |
El nombre calificado para la interfaz expuesta. En el caso de una vista sin interfaz consiste en el nombre completo de la clase del bean. |
Si |
Si un bean expone sólo una vista entonces el contenedor también tiene que dejar esa vista disponible no sólo bajo el nombre JNDI anterior, sino también en la siguiente ubicación:
java:global[/
El contenendor también debe dejar el nombre JNDI disponible en los espacios java:app y java:module para simplificar el acceso de clientes en el mismo módulo o aplicación.
java:app[/
java:module/
java:app es usado por los clientes que se ejecutan en la misma aplicación que el bean destino. El nombre del módulo es opcional para módulos individuales. java:module es usado por los clientes que se ejecutan en el mismo módulo que el bean destino.
Ejemplo 1:
Bean empaquetado en mybeans.jar dentro de myapp.ear sin un descriptor de despliegue
package com.pt.xyz; @Singleton public class BeanA { (...) }
El BeanA tiene una vista sin interfaz disponible bajo los siguientes nombres JNDI: - java:global/myapp/mybeans/BeanA - java:global/myapp/mybeans/BeanA!com.pt.xyz.BeanA - java:app/mybeans/BeanA - java:app/mybeans/BeanA!com.pt.xyz.BeanA - java:module/BeanA - java:module/BeanA!com.pt.xyz.BeanA
Ejemplo 2:
Bean empaquetado en in mybeans.jar sin descriptores de despliegue
package com.pt.xyz; @Stateless(name="MyBeanB") public class BeanB implements BLocal, BRemote { (...) } package com.pt.xyz; @Local public interface BLocal { (...) } package com.pt.abc; @Remote public interface BRemote { (...) }
BLocal estará disponible con los siguientes nombres JNDI: - java:global/mybeans/MyBeanB!com.pt.xyz.BLocal - java:app/MyBeanB!com.pt.xyz.BLocal - java:module/MyBeanB!com.pt.xyz.BLocal BRemote estará disponible con los siguientes nombres JNDI: - java:global/mybeans/MyBeanB!com.pt.abc.BRemote - java:app/MyBeanB!com.pt.abc.BRemote - java:module/MyBeanB!com.pt.abc.BRemote
Timer-Service
Existen varias aplicaciones que tienen requerimientos guiados por el tiempo. Por mucho tiempo se ignoraron estas necesidades, forzando a los desarrolladores a utilizar soluciones no estándar como Quartz o Flux. EJB 2.1 introdujo el concepto de Timer Service, pero tenía varias limitaciones.
Con EJB 3.1 la situación cambia para mejor. Hay dos formas de crear timers:
- Programáticamente, usando la interfaz TimerService ya existente. La interfaz fue mejorado desde la versión 2.1 para brindar más flexibilidad al crear timers.
- Declarativamente, usando anotaciones o en el descriptor de despliegue. De esta manera se puede definir un timer de manera estática para que sea creado automáticamente durante el inicio de la aplicación.
La anotación Schedule se utiliza para crear un timer de forma automática, y toma como parámetro el timeout correspondiente a la ejecución. Esta anotación se aplica al método que será utilizado como callback del timeout. En el siguiente ejemplo se definen dos timers, uno que expira cada lunes a la medianoche y el otro que expira el último día de cada mes.
@Stateless public class TimerEJB { @Schedule(dayOfWeek="Mon") public void itIsMonday(Timer timer) { (...) } @Schedule(dayOfMonth="Last") public void itIsEndOfMonth(Timer timer) { (...) } }
Un método puede estar anotado con más de un timer, como se ve a continuación, en donde se definen dos timers para el método mealTime, uno de los cuales expira todos los días a la 1pm y el otro expira a las 8pm.
@Stateless public class MealEJB { @Schedules( { @Schedule(hour="13"), @Schedule(hour="20") } public void mealTime(Timer timer) { (...) } }
Tanto los timers automáticos como programáticos pueden ser persistentes (predeterminado) o no-persistentes. Los timers no-persistentes no sobreviven a un apagado de la aplicación o una caida del contenenedor. La persistencia puede definirse usando el atributo persistente de la anotación, o pasando la clase TimerConfig como parámetro del método createTimer en la interfaz TimerService. Se mejoró a la interfaz Timer para incluir el método isPersistent.
Cada anotación Schedule para los timers persistentes se corresponde con un único timer, sin importar la cantidad de JVM sobre las cuales está distribuida la aplicación. Esto tiene un impacto importante sobre cómo se usan los timers en un ambiente con clusters. Supongamos que una aplicación necesita mantener un timer activo apuntando al siguiente evento activo. El timer se actualiza a medida que aparecen nuevos eventos. Antes de EJB 3.1 esto era relativamente facil de lograr usando el TimerService, a menos que la aplicación estuviera desplegada en más de una JVM. En ese caso, cuando un timer se creataba en una JVM no era visible en el resto de las JVMs. Esto significaba que debía adoptarse alguna estrategia para hacer visible al timer a las otras JVMs. Y hacer esto ocasionaba que el código tomara conocimiento del entorno en donde era desplegado, lo cual es una mala práctica. Con EJB 3.1 el desarrollador no tiene que preocuparse si la aplicación se despliegue en muchas JVM, ya que la coordinación la realiza el contenedor.
Un timer no-persistente creado automáticamente obtiene un timer nuevo creado para cada JVM sobre el contenedor que está desplegado.
La firma del método callback de timeout puede ser alguno de los siguientes: void
En cuanto al timer en si mismo hubo muchas mejoras. La expresión de timeout utiliza una sintaxis similar al del comando UNIX cron. Hay ocho atributos que pueden usarse en estas expresiones:
|
Atributo |
Valores permitidos |
Ejemplo |
|
second |
[0, 59] |
second = "10" |
|
minute |
[0, 59] |
minute = "30" |
|
hour |
[0, 23] |
hour = "10" |
|
dayOfMonth |
- [1, 31] - día del mes - Last - último día del mes - -[1, 7] - cantidad de días antes del fin de mes - {"1st", "2nd", "3rd", "4th", "5th", ..., "Last"} {"Sun", "Mon", "Tue", "Wed", "Thu", "Fri", "Sat"}- identifica una única ocurrencia en el mes |
dayOfMonth = "3" dayOfMonth = "Last" dayOfMonth = "-5" dayOfMonth = "1st Tue" |
|
month |
- [1, 12] - día del mes - {"Jan", "Feb", "Mar", "Apr", "May", "Jun", "Jul", "Aug", "Sep", "Oct", "Nov", "Dec"}- nombre del mes |
month = "7" month = "Jan" |
|
dayOfWeek |
- [0, 7]- día de la semana en donde 0 y 7 representan al domingo - {"Sun", "Mon", "Tue", "Wed", "Thu", "Fri", "Sat"}- nombres de la semana |
dayOfWeek = "5"
dayOfWeek = "Wed" |
|
year |
año calendario de cuatro dígitos |
year = "1978" |
|
timezone |
código de la zona horaria |
timezone = "America/New_York" |
Los valores provistos para cada atributo pueden expresarse en diferentes formas:
|
Tipo de expresión |
Descripcion |
Ejemplo |
|
Valor único |
Restringe al atributo a un único valor |
dayOfWeek = "Wed" |
|
Comodín |
Representa todos los valores posibles para el atributo |
month = "*" |
|
Lista |
Restringe al atributo a dos o más valores permitidos, separados por coma |
DayOfMonth = "3,10,23" dayOfWeek = "Wed,Sun" |
|
Rango |
Restringe al atributo a un rango inclusivo de valores |
year = "1978-1984" |
|
Incrementos |
Define una expresión x/y donde el atributo está restringido a cada valor y dentro del conjunto de valores permitidos, comenzando al momento x |
second = "*/10" - cada 10 segundos hour = "12/2"- cada dos horas comenzando al mediodía |
Todos los martes a las 7.30am @Schedule(hour = "7", minute = "30", dayOfWeek = "Tue") De lunes a viernes, a las 7, 15 y 20 horas @Schedule(hour = "7, 15, 20", dayOfWeek = "Mon-Fri") Cada hora de los domingos @Schedule(hour = "*", dayOfWeek = "0") Último viernes de diciembre, a las 12 @Schedule(hour = "12", dayOfMonth = "Last Fri", month="Dec") Tres días antes del fin de mes, para cada mes del 2009, a las 8pm @Schedule(hour = "20", dayOfMonth = "-3", year="2009") Cada 5 minutos de todas las horas, comenzando a las 3pm @Schedule(minute = "*/5", hour = "15/1")
La interfaz TimerService fue mejorada para poder crear timers programáticamente usando expresiones al estilo cron. Estas expresiones pueden representarse por una instancia de la clase ScheduleExpression, la cual puede pasarse como parámetro durante la creación del timer.
EJB Lite
Un contenedor de EJB que cumple con la especificación tiene que implementar un conjunto de APIs. Este conjunto ahora está dividido en dos categorías: mínimo y completo. El conjunto mínimo se llama EJB 3.1 Lite, y brinda un subconjunto de las características que pueden usarse en aplicaciones (aplicaciones EJB 3.1 Lite) que no necesitan del conjunto completo del API.
EJB Lite facilita la curva de aprendizaje, ya que los desarrolladores podrán crear aplicaciones sin tener que conocer el conjunto completo de características, contando con una curva de aprendizaje más suave. Además los proveedores comerciales pueden reducir los costos de licenciamiento. Muchas veces se escucha que uno paga la licencia del contenedor sin importar la cantidad de APIs que utilice la aplicación. Al hacer dos versiones de EJB (Completo y Lite) los proveedores pueden introducir licencias a precios diferenciados. Una aplicación puede empezar a pagar por lo que usa.
EJB 3.1 Lite incluye las siguientes características:
- Beans Stateless, Stateful y Singleton. Sólo hay vistas locales y sin interfaz, y sólo invocaciones sincrónicas.
- Transacciones gestionadas por el contenedory transacciones gestionadas por el bean.
- Seguridad declarativa y programática.
- Interceptores.
- Descriptores de despliegue.
Empaquetado de EJB simplificado
Un archivo ejb-jar es un módulo que empaqueta EJBs. Antes de EJB 3.1 todos los beans tenían que estar empaquetados en estos archivos. Como una buena parte de todas las aplicaciones Java EE contienen un front-end web y un back-end con EJB, esto significa que debe crearse un ear que contenga a la aplicación con dos módulos: un war y un ejb-jar. Esto es una buena práctica en el sentido que se crea una separación estructural clara entre el front-end y el back-end. Pero para las aplicaciones simples resulta demasiado.
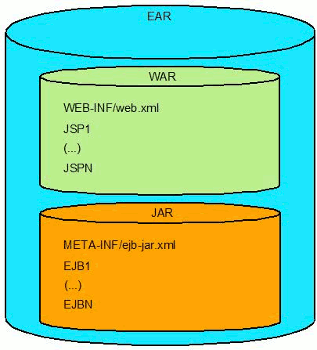
EJB 3.1 permite empaquetar EJBs dentro de un archivo war. Las clases pueden incluirse en el directorio WEB-INF/classes o en un archivo jar dentro de WEB-INF/lib. El war puede contener como máximo un archivo ejb-jar.xml, el cual puede estar ubicado en WEB-INF/ejb-jar.xml o en el directorio META-INF/ejb-jar.xml de un archivo jar.
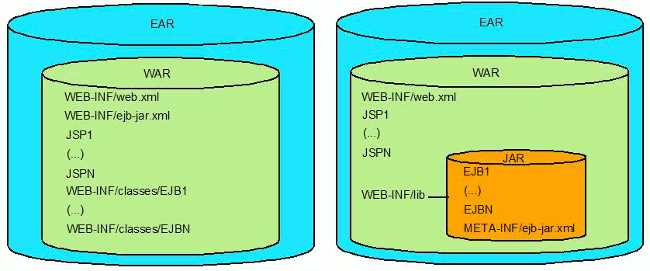
Cabe destacar que este empaquetado simplificado sólo debería usarse en aplicaciones simples. El resto de las aplicaciones se verá beneficiada con el empaquetado actual separado.
Contenedores EJB embebiles
A los EJB se los relaciona tradicionalmente con contenedores pesados Java EE, lo cual hace que resulten dificiles de usar en algunos contextos:
- Es dificil hacer una prueba unitaria de un bean.
- Un proceso batch simple standalone no puede beneficiarse del uso de EJBs a menos que exista un contenedor JavaEE que brinde los servicios necesarios.
- Se complica el uso de EJBs en aplicaciones de escritorio.
Una de las características más importantes de EJB 3.1 consiste en el soporte para contenedores embebibles. Un cliente Java SE ahora puede instanciar un contenedor EJB que se ejecuta dentro de su propia JVM y classloader. Este contenedor embebible provee un conjunto básico de servicios que le permiten al cliente beneficiarse del uso de EJBs sin necesitar de un contenedor Java EE.
Este contenedor embebible busca en el classpath para encontrar módulos EJB. Hay dos formas de calificar como módulo EJB:
- Un archivo ejb-jar.
- Un directorio que contiene un archivo META-INF/ejb-jar.xml o al menos una clase anotada como un EJB.
Un contenedor embebible tiene que soportar el subconjunto de APIs de EJB Lite. Los proveedores son libres de expandir este soporte para incluir el API completo de EJB 3.1.
La clase EJBContainer juega un rol central en el uso de contenedores embebibles. Esta clase brinda un método estático createEJBContainer que permite instanciar un contenedor nuevo. Tiene un método close que inicia el apagado del contenedor, causando que se invoquen todos los callback PreDestroy. Por último, tiene un método getContext que retorna un contexto de nombres que le permite al cliente realizar un lookup de referencias a Session Beans desplegados en el contenedor embebible.
@Singleton @Startup public class ByeEJB { private Logger log; @PostConstruct public void initByeEJB() { log.info("ByeEJB se está inicializando..."); (...) } public String sayBye() { log.info("ByeEJB está diciendo bye..."); return "Bye!"; } @PreDestroy public void destroyByeEJB() { log.info("ByeEJB está siendo destruido..."); (...) } } public class Client { private Logger log; public static void main(String args[]) { log.info("Iniciando el cliente..."); EJBContainer ec = EJBContainer.createEJBContainer(); log.info("Contenedor creado..."); Context ctx = ec.getContext(); //Gets the no-interface view ByeEJB byeEjb = ctx.lookup("java:global/bye/ByeEJB"); String msg = byeEjb.sayBye(); log.info("Se obtuvo el siguiente mensaje: " + msg); ec.close(); log.info("Terminando el cliente..."); } }
La salida del log al ejecutar el main() es: Iniciando el cliente... ByeEJB se está inicializando... Contenedor creado... ByeEJB está diciendo bye... Se obtuvo el siguiente mensaje: Bye! ByeEJB está siendo destruido... Terminando el cliente...
Lo mejor del resto
Además de todas estas características, hay varias mejores menores que simplifican o mejoran las funcionalidades existentes. Las mejoras más relavantes son:
- Un Stateful Bean ahor apuede usar las anotaciones AfterBegin, BeforeCompletion y AfterCompletion en vez de implementar la interfaz SessionSynchronization.
- Se puede indicar un timeout para un Stateful Bean, que consiste en la cantidad de tiempo que un Stateful Bean puede mantenerse inactivo antes de que el contenedor lo elimine. La anotación StatefulTimeout se utiliza para lograr esto.
- El contenedor está obligado a serializar las invocaciones a beans stateful y stateless. De manera predeterminada, está permitido tener llamadas concurrentes a los beans stateful, y queda en el contenedor el serializarlas. El desarrollador ahora puede usar la anotación ConcurrencyManagement(CONCURRENCY_NOT_ALLOWED) para indicar que un bean stateful no soporta peticiones concurrentes. En este caso, cuando un bean stateful está procesando una invocación de un cliente, y llega una segunda invocación (del mismo cliente o de otro), la segunda invocación recibirá un ConcurrentAccessException.
- La anotación AroundTimeout puede usarse para definir métodos de interceptor los métodos de timeout de un timer.
Conclusión
La especificación Java EE 6 está por quedar terminada, y la mayoría de las tecnologías que abarca están llegando a su versión final, todo con altas expectativas. Definitivamente 2009 va a ser un año importante para Java EE.
Muchas características y nuevas oportunidades surgen con EJB 3.1 EJB 3.1 le permite a los arquitectos y a los desarrollador contar con un conjunto rico de nuevas funcionalidades, permitiendo extender la cantidad de desafios que puede cubrir esta tecnología. Esta nueva versión demuestra mucha madurez, y hará que Java tenga una posición más sólida que nunca en el lado del servidor.
Basado en EJB 3.1 - A significant step towards maturity.
