 Los despliegues de aplicaciones Java suelen ser complicados, propensos a errores, y manuales, de forma que se generan demoras en hacer que el software quede disponible para los usuarios. En la primera parte de esta serie identificamos ocho patrones claves para crear un proceso de despliegue seguro, repetible y consistente. En esta segunda parte expandimos la discusión y presentamos siete patrones más que complemetan a los anteriores y con los que podremos crear un despliegue con un solo click.
Los despliegues de aplicaciones Java suelen ser complicados, propensos a errores, y manuales, de forma que se generan demoras en hacer que el software quede disponible para los usuarios. En la primera parte de esta serie identificamos ocho patrones claves para crear un proceso de despliegue seguro, repetible y consistente. En esta segunda parte expandimos la discusión y presentamos siete patrones más que complemetan a los anteriores y con los que podremos crear un despliegue con un solo click.
Los patrones de despliegue extendidos
El despliegue es un aspecto más en la creación de software, y es muy factible de automatizar. Los despliegues automatizados nos sirve porque generan un proceso confiables y repetibles: se mejora la certeza, velocidad y control del proceso de despliegue. A continuación vamos a expandir el primer artículo para cubrir siete patrones más, igualmente beneficiosos para los despliegues de aplicaciones.
- Integridad binaria, que asegura que el mismo artefacto sea promovido a los distintos ambientes de destino.
- Contenedor descartable, que pone a un ambiente de destino en un estado conocido para disminuir los errores de despliegue.
- Despliegue remoto, que asegura que los despliegues puedan comunicarse con múltiples equipos desde una máquina centralizada o cluster.
- Actualización de base de datos, que brinda una gestión centralizada y un proceso con scripts para aplicar cambios incrementales a la base de datos.
- Prueba de despliegue, que utiliza verificaciones antes y después del despliegue para comprobar que la aplicación funciona como se espera en un despliegue reciente.
- Rollback de ambiente, que realiza un rollback de la aplicación y de la base de datos si falla un despliegue.
- Archivos protegidos, que controla el acceso a ciertos archivos usados por el sistema de construcción.
El siguiente diagrama ilustra las relaciones entre los distintos patrones de despliegue que explicaremos a continuación (los patrones en gris fueron vistos en la parte 1).
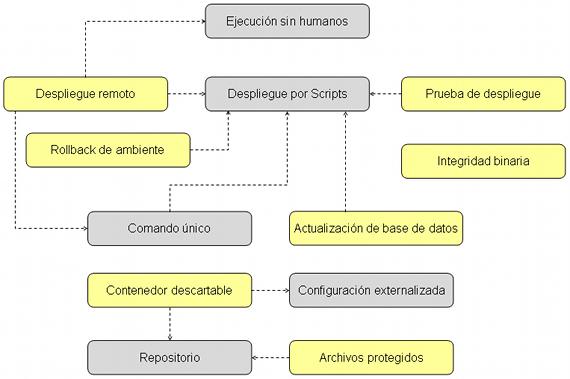
Estos siete patrones adicionales extienden a los ocho primeros (vistos anteriormente) para ayudarnos a crer una solución de despliegue con un único click.
Compilar una vez, desplegar en varios ambientes
Nombre: Integridad binaria
Patrón: para cada despliegue con un tag, se usa el mismo archivo (WAR, EAR) en cada ambiente de destino.
Anti-patrón: compilaciones separadas para cada ambiente de destino sobre el mismo tag.
Después de varios debates con colegas sobre este tema, estoy firmemente convencido en compilar una vez y desplegar en varios ambientes de destino, en vez de compilar y empaquetar in cada ambiente de destino. Por ejemplo, el artefacto producido para un despliegue Java Web es WAR o un EAR. Este archivo debería ser subido al repositorio de control de versiones y asignado un tag una única vez - como ser en el ambiente DEV.
A continuación ilustramos un ejemplo de la filosofía compilar una vez, desplegar a muchos; se genera el archivo brewery.war en la máquina de construcción, y este mismo archivo es desplegado en cada uno de los ambientes de destino.
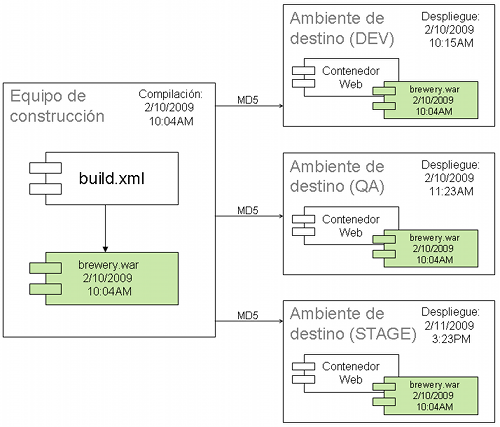
Ant brinda una tarea checksum (que utiliza el algoritmo MD5 como algoritmo de hash) para asegurarse que el archivo que fue compilado y empaquetado en la máquina de construcción sea el mismo que está siendo desplegado en cada ambiente de destino.
Algunos pueden argumentar que, aunque el artefacto pueda ser el mismo, la configuración de despliegue es diferente para cada ambiente. Es decir, cuando se utiliza un Comando Único y Despliegue por Scripts, muchos procesos automatizados pueden alterar la salida de la aplicación, sin importar si es el mismo archivo. Esto es cierto; sin embargo, podemos gastar varias horas innecesarias intentando descubrir el problema porque el software fue copilado y empaquetado usando una versión distinta de JDK en el ambiente STAGE del que se usó en el ambiente QA. Y también aumentan las probabilidades de fallos cuando los JAR que provienen de un repositorio de dependencias centralizado (como Ivy o Maven) difieren entre los ambientes de DEV y STAGE. Estos riesgos me convencieron que para asegurar la Integridad Binaria se debe compilar y empaquetar una única vez, para luego poder desplegar en varias ambientes.
Hacer despliegues baratos con contenedores descartables
Nombre: Contenedor descartable
Patrón: automatizar la instalación y configuración de los contenedores Web y la base de datos, al desacoplar la instalación y la configuración.
Anti-patrón: instalar manualmente y configurar los contenedores para cada ambiente de destino.
La Integración Continua nos ayuda a limpiar un entorno "sucio". El Contenedor Descartable reduce muchos de los problemas que ocurren cuando dependemos de contenedores persistentes. El patrón del Contenedor Descartable está basado en dos principios: quitar por completo todos los componentes del contenedor y separar la instalación del contenedor de su configuración. Esto puede parecer demasiado radical, en especial para ingenieros de sistemas, porque deja de asumir que los contenedores deben ser gestionados, y "oscurecidos", por un equipo separado, y que nunca pueden ser tocados por los demás. Sin embargo, considerando todos los problemas comunes y costosos que ocurren durante los despliegues, esta es un área donde todos los miembros del equipo pueden encontrar el mayor beneficio.
El patrón de Contenedor Descartable que se muestra a continuación se basa en la idea de que todo debería estar en el sistema (usando el patrón Repositorio, visto en la parte 1), y no en la cabeza de alguien.
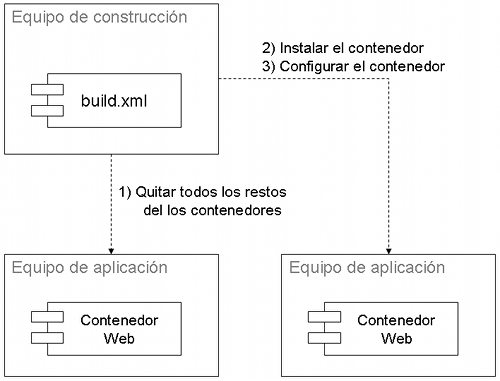
El siguiente script Ant descarga un zip de Tomcat desde Internet, quita cualquier rastro de despliegues anteriores, extrae, instala e inicia Tomcat:
<!-- Verificar si Tomcat está ejecutándose --> ... <exec executable="sh" osfamily="unix" dir="${tomcat.home}/bin" spawn="true"> <env key="NOPAUSE" value="true" /> <arg line="shutdown.sh" /> </exec> <delete dir="${tomcat.home}" /> <get src="${tomcat.binary.uri}/${tomcat.binary.file}" dest="${download.dir}/${tomcat.binary.file}" usetimestamp="true"/> <unzip dest="${target.dir}" src="${download.dir}/${tomcat.binary.file}" /> <exec osfamily="unix" executable="chmod" spawn="true"> <arg value="+x" /> <arg file="${tomcat.home}/bin/startup.sh" /> <arg file="${tomcat.home}/bin/shutdown.sh" /> </exec> <xmltask source="${appserver.server-xml.file}" dest="${appserver.server-xml.file}"> <attr path="/Server/Service[@name='${s.name}']/Connector[${port='${c.port}']" attr="proxyPort" value="${appserver.external.port}"/> <attr path="/Server/Service[${name='${s.name}']/Connector[${port='${c.port}']" attr="proxyName" value="${appserver.external.host}"/> </xmltask> <!-- Realizar otras configuraciones del contenedor --> ... <echo message="Iniciando tomcat en ${tomcat.home} con startup.sh" /> <exec executable="sh" osfamily="unix" dir="${tomcat.home}/bin" spawn="true"> <env key="NOPAUSE" value="true" /> <arg line="startup.sh" /> </exec>
Al poner un ambiente en un estado conocido, y desplegar contenedores de manera controlado, reducimos muchos errores comunes de despliegue que causan gran parte de los problemas de despliegue.
Ejecutar comandos en muchos ambientes externos
Nombre: Despliegue remoto
Patrón: usar una máquina centralizada o cluster para desplegar software hacia múltiples ambientes de destino
Anti-Patrón: aplicar despliegues locales manualmente en cada ambiente de destino
Es relativamente trivial hacer funcionar un despliegue en la máquina del desarrollador una vez que se instalaron la base de datos y el contenedor Web. Sin embargo, la diferencia entre desarrollo y producción es enorme. Si una organización tiene múltiples proyectos y distintos ambientes de destino (por ejemplo, ambientes de testing y de staging), suele existir la necesidad de administrar los despliegues de forma centralizada desde un único ambiente: una máquina o un cluster. Muy a menudo, los equipos usan un servidor de construcción para administrar los despliegues entre cada uno de estos ambientes de destino. En la parte 1 vimos el patrón de Ejecución Sin Humanos, en el cual se usan claves privadas y públicas para no tener que hacer un login manual a cada máquina. El Despliegue Remoto, como se ilustra a continuación, utiliza los patrones de Ejecución Sin Humanos, Comando Único y Despliegue por Scripts para facilitar el despliegue en equipos remotos.
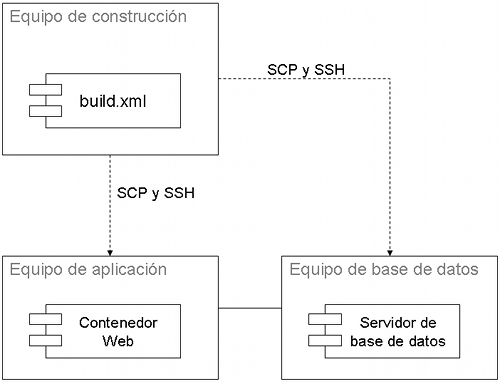
Para desplegar software remotamente desde un servidor de construcción centralizado, se necesitan utilizar mecanismos para copiar y ejecutar comandos remotos de forma segura. Los dos mecanismos que veremos usan Secure Copy (SCP) y Secure Shell (SSH). Desde un Despliegue por Scripts, como vemos a continuación, se genera un WAR en una máquina de construcción centralizada, el cual se copia remotamente a los ambientes de destino.
<target name="copy-tomcat-dist"> <scp file="${basedir}/target/brewery.war" trust="true" keyfile="${basedir}/config/id_dsa" username="bobama" passphrase="" todir="pduvall:G0theD!stance@myhostname:/usr/local/jakarta-tomcat/webapps" /> </target>
Después de que se copia el WAR de forma segura al ambiente destino remoto, se puede utilizar una tarea como SSHExec sobre un Java Secure Channel para ejecutar cualquier comando SSH - de forma remota desde la máquina de construcción centralizada. Un enfoque alternativo es hacer un ssh al ambiente remoto y ejecutar cualquier comando localmente. Esto disminuye el trafico remoto de ida y vuelta, y puede reducir los tiempos de despliegue.
Poner a la base de datos en un estado conocido
Nombre: Actualización de base de datos
Patrón: utilizar scripts y bases de datos para aplicar cambios incrementales a cada ambiente de destino.
Anti-Patrón: aplicar de forma manual los cambios a los datos y a la base de datos en cada ambiente de destino.
En la siguiente ilustración vemos un ejemplo de usar scripts automatizados para actualizar la base de datos como parte de un Despliegue por Scripts.
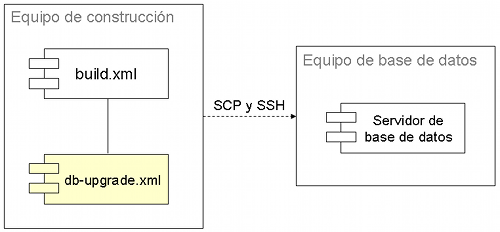
Como cualquier otra parte de un Despliegue por Scripts, los scripts de actualización de la base de datos están subidos al repositorio.
LiquiBase es una herramienta para aplicar cambios incrementales a una base de datos de forma que el mismo cambio se aplique a cada ambiente de destino como parte del Despliegue por Scripts. A continuación vemos un scripts SQL que se llama como parte de un log de cambios de LiquiBase. Después se invoca a este log de cambios (definido en XML) por el Despliegue por Scripts (se está implementado usando Ant).
<changeSet id="1" author="jbiden"> <sqlFile path="insert-distributor-data.sql"/> </changeSet>
Hay mucho material para leer y aprender respecto a automatizar la actualización de bases de datos, pero la idea es realizar actualizaciones como parte del Despliegue por Scripts, de forma que todos los cambios en la base de datos estén en el sistema, y no escritos en algún procedimiento o en la cabeza de alguien.
Despliegues con pruebas de humo
Nombre: Prueba del despliegue
Patrón: agregar un script de auto-verificación dentro del Script de Despliegue
Anti-patrón: verificar los despliegues ejecutando pruebas funcionales manuales que no hacen foco en los aspectos específicos del despliegue.
A continuación se ilustra un ejemplo de pruebas de despliegue en ejecución antes y después de un despliegue:
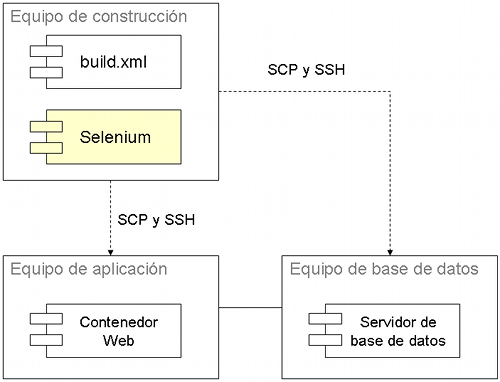
Podemos usar Ant para realizar pruebas antes del despliegue y verificar que estemos usando las versiones correctas de cada herramienta. En un Script de Despligue, el script puede verificar la existencia de puertos en uso (que causarían errores en el contenedor Web), verificar la conexión a la base de datos, y verificar si el contenedor está funcionando, junto con otras verificaciones internas del despliegue.
<condition property="ant.version.success"> <antversion atleast="${ant.check.version}" /> </condition> <antunit:assertPropertyEquals name="ant.version.success" value="true" /> <echo message="La versión de Ant es correcta." /> <echo message="Validando la versión de Java..."/> <condition property="java.major.version.correct"> <equals arg1="${ant.java.version}" arg2="${java.check.version.major}" /> </condition> <antunit:assertTrue message="El Java SDK debe ser 1.5+. \ Instale la versión correcta."> <isset property="java.major.version.correct"/> </antunit:assertTrue>
Una prueba de despliegue más completa puede comprobar que la funcionalidad de la aplicación es correcta. Al escribir pruebas funcionales automatizadas específicas del despliegue, usando una herramienta como Selenium para aplicaciones Web o Abbot para aplicaciones cliente, podemos verificar que los cambios se aplicaron correctamente. Podemos pensar en estas pruebas como en pruebas de humo: sólo necesitamos probar la funcionalidad que fue afectada por ese despliegue. Por ejemplo, la siguiente tabla muestra distintas formas de usar Selenium y otras herramientas para probar una aplicación Web:
| Prueba de despliegue | Descripción |
|---|---|
| Base de datos | Escribir una prueba funcional automatizada que inserte datos en la base de datos. Verificar que los datos queden en la base de datos. |
| Simple Mail Transfer Protocol (SMTP) | Escribir una prueba funcional automatizada que envia un mensaje de e-mail desde la aplicación. |
| Servicio Web | Usar una herramienta como SoapAPI para enviar datos aun servicio web y verificar la salida. |
| Contenedores web | Verificar que todos los servicios del contenedor web funcionen correctamente. |
| Lightweight Directory Access Protocol (LDAP) | Autenticarse via LDAP al usar la aplicación. |
| Logging | Escribir una prueba que escriba en el log usando el mecanismo de log de la aplicación. |
Las pruebas automáticas no son sólo para probar la funcionalidad del usuario. Se pueden crear grupos de pruebas que se enfoquen en las pruebas de despliegue, y así verificar la eficacia del despliegue, reduciendo errores y costos de desarrollo.
Hacer un rollback de todos los cambios del despligue
Nombre: Rollback de ambiente
Patrón: brindar un Comando Único de rollback de cambios luego de un despliegue fallido.
Anti-patrón: hacer un rollback manual de la aplicación y de los cambios en la base de datos.
En la ilustración vemos un rollback de los cambios en la base de datos (usando Actualización de Base de Datos) junto a un proceso automatizado para hacer un rollback de un despliegue web.
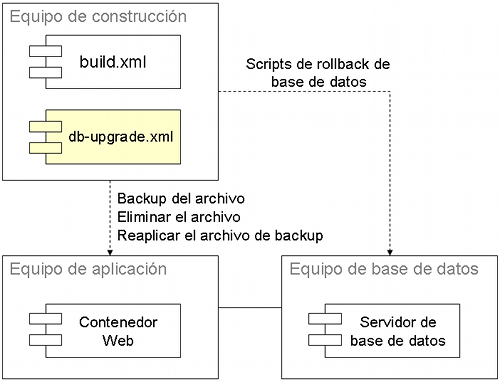
Aunque no estemos usando despliegues automatizados, es bueno tener una forma de deshacer los cambios cuando un despliegue falla. En algunos casos, cambios incorrectos pueden resultar en la caida del sistema, y costarle millones de dólares a la organización. Para realizar un Rollback de Ambiente necesitamos volver a los ambientes de destino a su estado anterior al despliegue. Para hacer esto, hacemos tener un script de rollback para cada cambio. Un despliegue web en general necesita más cambios para hacer rollback. Un ejemplo de un Rollback de Ambiente es copiar el archivo (por ejemplo, el WAR) anterior al despliegue y usar un script de rollback para la base de datos por cada cambio. También se necesita volver a aplicar los cambios en la configuración del contenedor web.
El siguiente script muestra un ejemplo de una sentencia de rollback por cada sentencia usando LiquiBase. Se agrega una tabla nueva llamada brewery y a la vez se especifica la sentencia de rollback (dropTable) correspondiente.
<changeSet id="rollback-database-changes" author="bobama"> <createTable tableName="brewery"> <column name="id" type="int"/> </createTable> <rollback> <dropTable tableName="brewery"/> </rollback> </changeSet>
Este ejemplo sencillo es a modo ilustrativo, y no para trivializar el rollback. El proceos de revertir la aplicación a un despliegue anterior es complejo y costoso de realizar (y de automatizar). El tiempo invertido en escribir los scripts de rollback deben estar en proporción con el costo de una falla en el despliegue.
Proteger a la información de los curiosos
Nombre: Archivos protegidos
Patrón: usando un repositorio, se comparten los archivos a los miembros del equipo autorizados.
Anti-patrón: los archivos se administran en las máquinas de los miembros del equipo, o se almacen en unidades compartidas accesibles por los miembros del equipo.
La siguiente ilustración muestra un repositorio de control de versiones protegido, que se usa para almacenar archivos que sólo las personas o los sistemas autorizados pueden acceder.
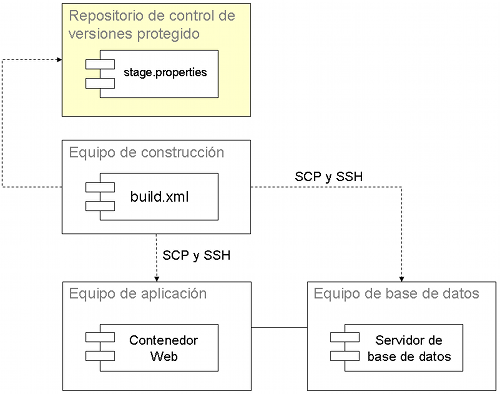
En algunos casos, no todos los miembros del equipo deben acceder a datos específicos de algunos ambientes. Sin embargo, mantener esta información separada de los scripts de despliegue puede hacer que estos scripts no funcionen. Cuando hablamos del patrón Ejecución Sin Humanos, se describió el uso de claves SSH con la herrameinta Java Secure Channel para copiar archivos y ejecutar comandos remotos de forma segura sin necesidad de que un humano ingrese comandos. Las propiedades que se usan con la Configuración Externalizada pueden tener datos que no deberían ver todos los miembros del equipo. Una técnica que se puede usar para asegurar la Ejecución Sin Humanos y a la vez proteger a los datos de los archivos .properties es subir estos archivos a un repositorio protegido.
En el siguiente ejemplo configuramos un repositorio Subversion sobre Apache para denegar el acceso a un directorio a todos, y luego se agregan explícitamente a usuarios específicos:
Order deny,allow
Deny from all
Allow bobama,jbiden,hclinton
Al proteger el acceso al repositorio de Subversion, un Script de Despliegue puede acceder a las propiedades como uno de los usuarios habilitados sin necesidad de ingresar una contraseña, permitiendo así una Ejecución Sin Humanos según las claves SSH.
El despliegue con un único click
Estos 15 patrones que catalogamos en la serie cubre probablemente el 80% de las situaciones de despliegue. Cada uno de estos patrones está pensado para ayudarnos a lograr un verdadero despliegue con un único click para cada ambiente de destino.
¡Y espero que dejen de sufrir en los despliegues!
Basado en Deployment automation patterns, part 2.
