Diferencia entre revisiones de «Spring Data»
(→Mas) |
|||
| Línea 195: | Línea 195: | ||
==Mas== | ==Mas== | ||
| + | |||
| + | ===SELECT DISTINCT=== | ||
| + | |||
| + | ====Situación a resolver==== | ||
| + | Necesitamos recuperar todos los clientes, tal que alguno de los servicios de los clientes cumpla con una condición determinada. | ||
| + | |||
| + | ====Primera solución==== | ||
| + | Creamos un método: | ||
| + | List<Cliente> findByServiciosEstado(EstadosServicios estado); | ||
| + | |||
| + | ====Problema==== | ||
| + | El método traía repetidos los clientes por cada uno de sus servicios que cumplían con la condición. | ||
| + | |||
| + | =====Contexto===== | ||
| + | * Spring Data JPA, version 1.0.3.RELEASE. | ||
| + | |||
| + | =====Solución===== | ||
| + | Al método le agregamos la keyword Distinct delante del By: | ||
| + | List<Cliente> findDistinctByServiciosEstado(EstadosServicios estado); | ||
| + | |||
| + | =====Comentario adicional===== | ||
| + | El problema de esto es que la keyword no está en la [http://static.springsource.org/spring-data/data-jpa/docs/current/reference/html/#repository-query-keywords| documentación oficial de Spring Data JPA]. | ||
| + | Sin embargo, encontramos una [https://jira.springsource.org/browse/DATAJPA-174?page=com.atlassian.streams.streams-jira-plugin:activity-stream-issue-tab| issue en el Jira de Spring Data JPA] sobre el tema. | ||
| + | |||
| + | Por último, [http://static.springsource.org/spring-data/data-jpa/docs/1.0.0.RELEASE/changelog.txt| en el changelog de la versión] se indica que está soportado. | ||
| + | |||
| + | |||
| + | ===Proyecto de ejemplo=== | ||
Pueden descargarse un proyecto de ejemplo haciendo un checkout mediante un cliente de SVN de: | Pueden descargarse un proyecto de ejemplo haciendo un checkout mediante un cliente de SVN de: | ||
http://dosideas-aplicaciones-modelo.googlecode.com/svn/trunk/spring-data/trunk | http://dosideas-aplicaciones-modelo.googlecode.com/svn/trunk/spring-data/trunk | ||
Revisión del 15:48 15 jun 2012
Contenido
Introducción
La herramienta que encontramos útil para dejar de hacer manualmente las implementaciones de los DAO que suelen ser siempre de la misma manera, fué a través de Spring Data JPA. [1]
Este framework nos permite, siguiendo una serie de normas que nos establece, crear interfaces de DAOs definiendo métodos y NO realizar ninguna implementación. Es decir, dejamos la responsabilidad de la implementación al framework, el cuál hará la implementación en tiempo de corrida. Para ello, el framework básicamente lo que hace es buscar, dado un paquete que le indicamos por configuración, todas las interfaces que hereden de org.springframework.data.repository.Repository<T, ID extends Serializable> ya sea directa o indirectamente.

Configuración
Dependencias (Utilizando Maven)
Para trabajar con Spring Data JPA, solo debemos agregar la dependencia:
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-jpa</artifactId>
<version>1.0.3.RELEASE</version>
</dependency>
Siempre y cuando contemos con una configuración de persistencia que utilice:
<bean id="transactionManager" class="org.springframework.orm.jpa.JpaTransactionManager">
<property name="entityManagerFactory" ref="entityManagerFactory" />
<property name="jpaDialect">
<bean class="org.springframework.orm.jpa.vendor.HibernateJpaDialect" />
</property>
</bean>
<bean id="entityManagerFactory" class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean">
<property name="dataSource" ref="defaultDataSource" />
<property name="jpaVendorAdapter">
<bean class="org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter">
<property name="generateDdl" value="false" />
</bean>
</property>
</bean>
Configurando el paquete a escanear
En el applicationContext.xml:
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:jpa="http://www.springframework.org/schema/data/jpa" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.1.xsd http://www.springframework.org/schema/data/jpa http://www.springframework.org/schema/data/jpa/spring-jpa.xsd"> . . . <jpa:repositories base-package="com.th.ctc.dao" /> . . . </beans>
Implementación
El ejemplo fácil
Definiendo la interfaz del DAO
Para este ejemplo sencillo, la interfaz del DAO va a quedar sin métodos definidos explicitamente, pero con todos aquellos que estamos heredando.
import org.springframework.data.repository.CrudRepository;
import com.th.ctc.domain.Cliente;
/**
* Interfaz del DAO para la entidad {@link Cliente}. Esta interfaz NO tiene una
* implementacion concreta dado que al extender de Repository la implementacion
* la hace en runtime Spring Data JPA.
*
* @author Alguien.
*/
public interface ClienteDao extends CrudRepository<Cliente, Long> {
}
Usando el DAO desde el Service
Hasta acá llegamos. A partir de ahora no hay mas código vinculado con el DAO más que el uso de los métodos que estamos exponiendo en la interfaz que nosotros mismos creamos. Por lo tanto nuestro Service sería algo como:
/**
* DAO de clientes.
*/
@Autowired
private ClienteDao clienteDao;
@Override
public List<Cliente> buscarTodos() {
return (List<Cliente>) clienteDao.findAll(); //El método findAll() proviene de CrudRepository
}
Test
Como no hay una implementación concreta, y de haber, no la hacemos nosotros sino que estamos delegando la responsabilidad al framework, no hacemos tests de la capa DAO, pero si del Service donde probamos que estamos utilizando correctamente lo que nos provee Spring DATA JPA además claro de la lógica propia del Service.
El ejemplo habitual
Definiendo la interfaz del DAO
Para este ejemplo sencillo, la interfaz del DAO va a quedar sin métodos definidos explicitamente, pero con todos aquellos que estamos heredando.
import org.springframework.data.repository.PagingAndSortingRepository;
import com.th.ctc.domain.Usuario;
/**
* Interfaz del DAO para la entidad {@link Usuario}. Esta interfaz NO tiene una
* implementacion concreta dado que al extender de Repository la implementación
* la hace en runtime Spring Data JPA.
*
* @author Alguien.
*/
public interface UsuarioDao extends PagingAndSortingRepository<Usuario, Long> {
}
Usando el DAO desde el Service
Hasta acá llegamos. A partir de ahora no hay mas código vinculado con el DAO más que el uso de los métodos que estamos exponiendo en la interfaz que nosotros mismos creamos. Por lo tanto nuestro Service sería algo como:
/**
* DAO de usuarios.
*/
@Autowired
private UsuarioDao usuarioDao;
@Override
public List<Usuario> buscarTodos() {
// El método findAll(Sort) proviene de PagingAndSortingRepository y con el String "apellido" (es el nombre del
// atributo de clase de la entidad Usuario) estamos indicando que se ordenaran los resultados por ese campo
return (List<Usuario>) usuarioDao.findAll(new Sort("apellido"));
}
Test
Como no hay una implementación concreta, y de haber, no la hacemos nosotros sino que estamos delegando la responsabilidad al framework, no hacemos tests de la capa DAO, pero si del Service donde probamos que estamos utilizando correctamente lo que nos provee Spring DATA JPA además claro de la lógica propia del Service.
El ejemplo dificil
Supongamos que ahora necesitamos 2 cosas: Por un lado, recuperar todos los elementos de una entidad, recuperar uno solo en base al ID y etc., y por otro, generar un archivo Excel con información recuperada de una consulta a una base de datos muy específica. Para lograr esto, aprovechando esta herramienta, necesitamos 2 interfaces del DAO. Una para definir estos métodos tan complejos que necesitamos, y otra para utilizar de la misma manera que en el ejemplo fácil.
¿Pero entonces el Service tiene que utilizar 2 DAOs distintos sobre la misma entidad?
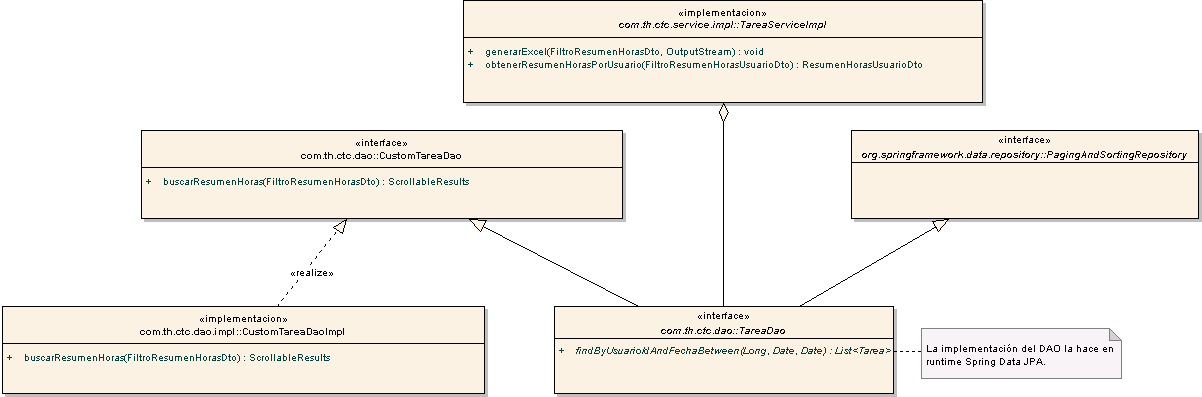
No. Antes que nada, veamos un diagrama de clases para que veamos por qué este es el ejemplo dificil: Diagrama de clases
{kind=link}
Es decir, tenemos un Service (TareaServiceImpl) que utiliza un DAO (TareaDao). Nada nuevo hasta acá. Sin embargo, este TareaDao no solo hereda de Repository al heredar de org.springframework.data.repository.PagingAndSortingRepository, sino que también está heredando de una interfaz definida por nosotros (CustomTareaDao).
¿Por qué necesitamos esto?
Bueno, por que si bien podemos definir métodos en la interfaz que hereda de Repository, estos métodos tienen que seguir una nomenclatura específica para que el framework pueda hacer la implementación y, además, porque no podemos definir métodos que no queremos que los implemente Spring Data JPA para implementarlos nosotros.
Definiendo la interfaz del DAO
import java.util.Date;
import java.util.List;
import org.springframework.data.domain.Sort;
import org.springframework.data.repository.PagingAndSortingRepository;
import com.th.ctc.domain.Tarea;
/**
* Interfaz el DAO de las {@link Tarea} implementado por Spring Data JPA.
*
* @author Alguien.
*/
public interface TareaDao extends PagingAndSortingRepository<Tarea, Long>, CustomTareaDao {
/**
* Recupera todas las tareas del usuario que le pasamos, para la fecha dada.
*
* @author Alguien.
* @param idUsuario
* {@link Long} con el ID del usuario duenio de la tarea.
* @param fechaDesde
* {@link Date} la fecha desde la cual se buscara.
* @param fechaHasta
* {@link Date} la fecha hasta la cual se buscara.
* @param sort
* {@link Sort} de Spring Data JPA utilizado para ordenar los
* resultados segun cierto criterio.
* @return {@link List<Tarea>} Las tareas encontradas.
*/
List<Tarea> findByUsuarioIdAndFechaBetween(Long idUsuario, Date fechaDesde, Date fechaHasta, Sort sort);
}
Como vemos, estamos definiendo un método findByUsuarioIdAndFechaBetween que sigue la nomenclatura del framework para recuperar un listado de tareas en base al Id del Usuario que le pasamos, entre un rango de fechas dado, y que al definir con esta nomenclatura hacemos que la implementación quede a cargo del framework.
Usando el DAO desde el Service
Ahora, nuestro Service cuenta con un DAO que tiene:
- Métodos definidos en él;
- Métodos provistos por PagingAndSortingRepository;
- Métodos provistos por CustomTareaDao.
¿Y las implementaciones?
Las implementaciones de los métodos definidos en TareaDao y los heredados de PagingAndSortingRepository, nos las va a proveer el framework. Y para la interfaz CustomTareaDao nosotros debemos definir nuestro DaoImpl común y corriente.
Test
A la hora de testear, debemos tener un test (en nuestro caso es TareaDaoComponenteTest) que testee de la interfaz DAO que exponemos (es decír, TareaDao):
- Los métodos definidos manualmente en el DAO siguiendo la nomenclatura específica del framework. Ej: List<Tarea> findByUsuarioIdAndFechaBetween(Long idUsuario, Date fechaDesde, Date fechaHasta, Sort sort);
- Los métodos definidos en la interfaz creada para los métodos específicos (CustomTareaDao). Ej: ScrollableResults buscarResumenHoras(FiltroResumenHorasDto filtro);
Test
Como estamos delegando la responsabilidad de la implementación del DAO en un framework, y como ni siquiera sabemos como es la implementación dado que se produce en runtime, decidimos no testear aquellos métodos ya tenemos definidos al heredar de alguna de las interfaces que nos provee la herramienta. Sin embargo, sí decidimos testear la capa del Service donde probamos que estamos utilizando correctamente lo que nos provee Spring DATA JPA, además claro de la lógica propia del Service.
Mas
SELECT DISTINCT
Situación a resolver
Necesitamos recuperar todos los clientes, tal que alguno de los servicios de los clientes cumpla con una condición determinada.
Primera solución
Creamos un método:
List<Cliente> findByServiciosEstado(EstadosServicios estado);
Problema
El método traía repetidos los clientes por cada uno de sus servicios que cumplían con la condición.
Contexto
- Spring Data JPA, version 1.0.3.RELEASE.
Solución
Al método le agregamos la keyword Distinct delante del By:
List<Cliente> findDistinctByServiciosEstado(EstadosServicios estado);
Comentario adicional
El problema de esto es que la keyword no está en la documentación oficial de Spring Data JPA. Sin embargo, encontramos una issue en el Jira de Spring Data JPA sobre el tema.
Por último, en el changelog de la versión se indica que está soportado.
Proyecto de ejemplo
Pueden descargarse un proyecto de ejemplo haciendo un checkout mediante un cliente de SVN de:
http://dosideas-aplicaciones-modelo.googlecode.com/svn/trunk/spring-data/trunk